Matthew Palmer: Not all TLDs are Created Equal
 In light of the recent cancellation of the
In light of the recent cancellation of the queer.af domain registration by the Taliban, the fragile and difficult nature of country-code top-level domains (ccTLDs) has once again been comprehensively demonstrated.
Since many people may not be aware of the risks, I thought I d give a solid explainer of the whole situation, and explain why you should, in general, not have anything to do with domains which are registered under ccTLDs.
Top-level What-Now?
A top-level domain (TLD) is the last part of a domain name (the collection of words, separated by periods, after the https:// in your web browser s location bar).
It s the com in example.com, or the af in queer.af.
There are two kinds of TLDs: country-code TLDs (ccTLDs) and generic TLDs (gTLDs).
Despite all being TLDs, they re very different beasts under the hood.
What s the Difference?
Generic TLDs are what most organisations and individuals register their domains under: old-school technobabble like com , net , or org , historical oddities like gov , and the new-fangled world of words like tech , social , and bank .
These gTLDs are all regulated under a set of rules created and administered by ICANN (the Internet Corporation for Assigned Names and Numbers ), which try to ensure that things aren t a complete wild-west, limiting things like price hikes (well, sometimes, anyway), and providing means for disputes over names1.
Country-code TLDs, in contrast, are all two letters long2, and are given out to countries to do with as they please.
While ICANN kinda-sorta has something to do with ccTLDs (in the sense that it makes them exist on the Internet), it has no authority to control how a ccTLD is managed.
If a country decides to raise prices by 100x, or cancel all registrations that were made on the 12th of the month, there s nothing anyone can do about it.
If that sounds bad, that s because it is.
Also, it s not a theoretical problem the Taliban deciding to asssert its bigotry over the little corner of the Internet namespace it has taken control of is far from the first time that ccTLDs have caused grief.
Shifting Sands
The queer.af cancellation is interesting because, at the time the domain was reportedly registered, 2018, Afghanistan had what one might describe as, at least, a different political climate.
Since then, of course, things have changed, and the new bosses have decided to get a bit more active.
Those running queer.af seem to have seen the writing on the wall, and were planning on moving to another, less fraught, domain, but hadn t completed that move when the Taliban came knocking.
The Curious Case of Brexit
When the United Kingdom decided to leave the European Union, it fell foul of the EU s rules for the registration of domains under the eu ccTLD3.
To register (and maintain) a domain name ending in .eu, you have to be a resident of the EU.
When the UK ceased to be part of the EU, residents of the UK were no longer EU residents.
Cue much unhappiness, wailing, and gnashing of teeth when this was pointed out to Britons.
Some decided to give up their domains, and move to other parts of the Internet, while others managed to hold onto them by various legal sleight-of-hand (like having an EU company maintain the registration on their behalf).
In any event, all very unpleasant for everyone involved.
Geopolitics on the Internet?!?
After Russia invaded Ukraine in February 2022, the Ukranian Vice Prime Minister asked ICANN to suspend ccTLDs associated with Russia.
While ICANN said that it wasn t going to do that, because it wouldn t do anything useful, some domain registrars (the companies you pay to register domain names) ceased to deal in Russian ccTLDs, and some websites restricted links to domains with Russian ccTLDs.
Whether or not you agree with the sort of activism implied by these actions, the fact remains that even the actions of a government that aren t directly related to the Internet can have grave consequences for your domain name if it s registered under a ccTLD.
I don t think any gTLD operator will be invading a neighbouring country any time soon.
Money, Money, Money, Must Be Funny
When you register a domain name, you pay a registration fee to a registrar, who does administrative gubbins and causes you to be able to control the domain name in the DNS.
However, you don t own that domain name4 you re only renting it.
When the registration period comes to an end, you have to renew the domain name, or you ll cease to be able to control it.
Given that a domain name is typically your brand or identity online, the chances are you d prefer to keep it over time, because moving to a new domain name is a massive pain, having to tell all your customers or users that now you re somewhere else, plus having to accept the risk of someone registering the domain name you used to have and capturing your traffic it s all a gigantic hassle.
For gTLDs, ICANN has various rules around price increases and bait-and-switch pricing that tries to keep a lid on the worst excesses of registries.
While there are any number of reasonable criticisms of the rules, and the Internet community has to stay on their toes to keep ICANN from totally succumbing to regulatory capture, at least in the gTLD space there s some degree of control over price gouging.
On the other hand, ccTLDs have no effective controls over their pricing.
For example, in 2008 the Seychelles increased the price of .sc domain names from US$25 to US$75. No reason, no warning, just pay up .
Who Is Even Getting That Money?
A closely related concern about ccTLDs is that some of the cool ones are assigned to countries that are not great.
The poster child for this is almost certainly Libya, which has the ccTLD ly .
While Libya was being run by a terrorist-supporting extremist, companies thought it was a great idea to have domain names that ended in .ly.
These domain registrations weren t (and aren t) cheap, and it s hard to imagine that at least some of that money wasn t going to benefit the Gaddafi regime.
Similarly, the British Indian Ocean Territory, which has the io ccTLD, was created in a colonialist piece of chicanery that expelled thousands of native Chagossians from Diego Garcia.
Money from the registration of .io domains doesn t go to the (former) residents of the Chagos islands, instead it gets paid to the UK government.
Again, I m not trying to suggest that all gTLD operators are wonderful people, but it s not particularly likely that the direct beneficiaries of the operation of a gTLD stole an island chain and evicted the residents.
Are ccTLDs Ever Useful?
The answer to that question is an unqualified maybe .
I certainly don t think it s a good idea to register a domain under a ccTLD for vanity purposes: because it makes a word, is the same as a file extension you like, or because it looks cool.
Those ccTLDs that clearly represent and are associated with a particular country are more likely to be OK, because there is less impetus for the registry to try a naked cash grab.
Unfortunately, ccTLD registries have a disconcerting habit of changing their minds on whether they serve their geographic locality, such as when auDA decided to declare an open season in the .au namespace some years ago.
Essentially, while a ccTLD may have geographic connotations now, there s not a lot of guarantee that they won t fall victim to scope creep in the future.
Finally, it might be somewhat safer to register under a ccTLD if you live in the location involved.
At least then you might have a better idea of whether your domain is likely to get pulled out from underneath you.
Unfortunately, as the .eu example shows, living somewhere today is no guarantee you ll still be living there tomorrow, even if you don t move house.
In short, I d suggest sticking to gTLDs.
They re at least lower risk than ccTLDs.
+1, Helpful
If you ve found this post informative, why not buy me a refreshing beverage?
My typing fingers (both of them) thank you in advance for your generosity.
Footnotes
-
don t make the mistake of thinking that I approve of ICANN or how it operates; it s an omnishambles of poor governance and incomprehensible decision-making.
-
corresponding roughly, though not precisely (because everything has to be complicated, because humans are complicated), to the entries in the ISO standard for Codes for the representation of names of countries and their subdivisions , ISO 3166.
-
yes, the EU is not a country; it s part of the roughly, though not precisely caveat mentioned previously.
-
despite what domain registrars try very hard to imply, without falling foul of deceptive advertising regulations.
Shifting Sands
The queer.af cancellation is interesting because, at the time the domain was reportedly registered, 2018, Afghanistan had what one might describe as, at least, a different political climate.
Since then, of course, things have changed, and the new bosses have decided to get a bit more active.
Those running queer.af seem to have seen the writing on the wall, and were planning on moving to another, less fraught, domain, but hadn t completed that move when the Taliban came knocking.
The Curious Case of Brexit
When the United Kingdom decided to leave the European Union, it fell foul of the EU s rules for the registration of domains under the eu ccTLD3.
To register (and maintain) a domain name ending in .eu, you have to be a resident of the EU.
When the UK ceased to be part of the EU, residents of the UK were no longer EU residents.
Cue much unhappiness, wailing, and gnashing of teeth when this was pointed out to Britons.
Some decided to give up their domains, and move to other parts of the Internet, while others managed to hold onto them by various legal sleight-of-hand (like having an EU company maintain the registration on their behalf).
In any event, all very unpleasant for everyone involved.
Geopolitics on the Internet?!?
After Russia invaded Ukraine in February 2022, the Ukranian Vice Prime Minister asked ICANN to suspend ccTLDs associated with Russia.
While ICANN said that it wasn t going to do that, because it wouldn t do anything useful, some domain registrars (the companies you pay to register domain names) ceased to deal in Russian ccTLDs, and some websites restricted links to domains with Russian ccTLDs.
Whether or not you agree with the sort of activism implied by these actions, the fact remains that even the actions of a government that aren t directly related to the Internet can have grave consequences for your domain name if it s registered under a ccTLD.
I don t think any gTLD operator will be invading a neighbouring country any time soon.
Money, Money, Money, Must Be Funny
When you register a domain name, you pay a registration fee to a registrar, who does administrative gubbins and causes you to be able to control the domain name in the DNS.
However, you don t own that domain name4 you re only renting it.
When the registration period comes to an end, you have to renew the domain name, or you ll cease to be able to control it.
Given that a domain name is typically your brand or identity online, the chances are you d prefer to keep it over time, because moving to a new domain name is a massive pain, having to tell all your customers or users that now you re somewhere else, plus having to accept the risk of someone registering the domain name you used to have and capturing your traffic it s all a gigantic hassle.
For gTLDs, ICANN has various rules around price increases and bait-and-switch pricing that tries to keep a lid on the worst excesses of registries.
While there are any number of reasonable criticisms of the rules, and the Internet community has to stay on their toes to keep ICANN from totally succumbing to regulatory capture, at least in the gTLD space there s some degree of control over price gouging.
On the other hand, ccTLDs have no effective controls over their pricing.
For example, in 2008 the Seychelles increased the price of .sc domain names from US$25 to US$75. No reason, no warning, just pay up .
Who Is Even Getting That Money?
A closely related concern about ccTLDs is that some of the cool ones are assigned to countries that are not great.
The poster child for this is almost certainly Libya, which has the ccTLD ly .
While Libya was being run by a terrorist-supporting extremist, companies thought it was a great idea to have domain names that ended in .ly.
These domain registrations weren t (and aren t) cheap, and it s hard to imagine that at least some of that money wasn t going to benefit the Gaddafi regime.
Similarly, the British Indian Ocean Territory, which has the io ccTLD, was created in a colonialist piece of chicanery that expelled thousands of native Chagossians from Diego Garcia.
Money from the registration of .io domains doesn t go to the (former) residents of the Chagos islands, instead it gets paid to the UK government.
Again, I m not trying to suggest that all gTLD operators are wonderful people, but it s not particularly likely that the direct beneficiaries of the operation of a gTLD stole an island chain and evicted the residents.
Are ccTLDs Ever Useful?
The answer to that question is an unqualified maybe .
I certainly don t think it s a good idea to register a domain under a ccTLD for vanity purposes: because it makes a word, is the same as a file extension you like, or because it looks cool.
Those ccTLDs that clearly represent and are associated with a particular country are more likely to be OK, because there is less impetus for the registry to try a naked cash grab.
Unfortunately, ccTLD registries have a disconcerting habit of changing their minds on whether they serve their geographic locality, such as when auDA decided to declare an open season in the .au namespace some years ago.
Essentially, while a ccTLD may have geographic connotations now, there s not a lot of guarantee that they won t fall victim to scope creep in the future.
Finally, it might be somewhat safer to register under a ccTLD if you live in the location involved.
At least then you might have a better idea of whether your domain is likely to get pulled out from underneath you.
Unfortunately, as the .eu example shows, living somewhere today is no guarantee you ll still be living there tomorrow, even if you don t move house.
In short, I d suggest sticking to gTLDs.
They re at least lower risk than ccTLDs.
+1, Helpful
If you ve found this post informative, why not buy me a refreshing beverage?
My typing fingers (both of them) thank you in advance for your generosity.
Footnotes
-
don t make the mistake of thinking that I approve of ICANN or how it operates; it s an omnishambles of poor governance and incomprehensible decision-making.
-
corresponding roughly, though not precisely (because everything has to be complicated, because humans are complicated), to the entries in the ISO standard for Codes for the representation of names of countries and their subdivisions , ISO 3166.
-
yes, the EU is not a country; it s part of the roughly, though not precisely caveat mentioned previously.
-
despite what domain registrars try very hard to imply, without falling foul of deceptive advertising regulations.
.eu, you have to be a resident of the EU.
When the UK ceased to be part of the EU, residents of the UK were no longer EU residents.
Cue much unhappiness, wailing, and gnashing of teeth when this was pointed out to Britons.
Some decided to give up their domains, and move to other parts of the Internet, while others managed to hold onto them by various legal sleight-of-hand (like having an EU company maintain the registration on their behalf).
In any event, all very unpleasant for everyone involved.
Geopolitics on the Internet?!?
After Russia invaded Ukraine in February 2022, the Ukranian Vice Prime Minister asked ICANN to suspend ccTLDs associated with Russia.
While ICANN said that it wasn t going to do that, because it wouldn t do anything useful, some domain registrars (the companies you pay to register domain names) ceased to deal in Russian ccTLDs, and some websites restricted links to domains with Russian ccTLDs.
Whether or not you agree with the sort of activism implied by these actions, the fact remains that even the actions of a government that aren t directly related to the Internet can have grave consequences for your domain name if it s registered under a ccTLD.
I don t think any gTLD operator will be invading a neighbouring country any time soon.
Money, Money, Money, Must Be Funny
When you register a domain name, you pay a registration fee to a registrar, who does administrative gubbins and causes you to be able to control the domain name in the DNS.
However, you don t own that domain name4 you re only renting it.
When the registration period comes to an end, you have to renew the domain name, or you ll cease to be able to control it.
Given that a domain name is typically your brand or identity online, the chances are you d prefer to keep it over time, because moving to a new domain name is a massive pain, having to tell all your customers or users that now you re somewhere else, plus having to accept the risk of someone registering the domain name you used to have and capturing your traffic it s all a gigantic hassle.
For gTLDs, ICANN has various rules around price increases and bait-and-switch pricing that tries to keep a lid on the worst excesses of registries.
While there are any number of reasonable criticisms of the rules, and the Internet community has to stay on their toes to keep ICANN from totally succumbing to regulatory capture, at least in the gTLD space there s some degree of control over price gouging.
On the other hand, ccTLDs have no effective controls over their pricing.
For example, in 2008 the Seychelles increased the price of .sc domain names from US$25 to US$75. No reason, no warning, just pay up .
Who Is Even Getting That Money?
A closely related concern about ccTLDs is that some of the cool ones are assigned to countries that are not great.
The poster child for this is almost certainly Libya, which has the ccTLD ly .
While Libya was being run by a terrorist-supporting extremist, companies thought it was a great idea to have domain names that ended in .ly.
These domain registrations weren t (and aren t) cheap, and it s hard to imagine that at least some of that money wasn t going to benefit the Gaddafi regime.
Similarly, the British Indian Ocean Territory, which has the io ccTLD, was created in a colonialist piece of chicanery that expelled thousands of native Chagossians from Diego Garcia.
Money from the registration of .io domains doesn t go to the (former) residents of the Chagos islands, instead it gets paid to the UK government.
Again, I m not trying to suggest that all gTLD operators are wonderful people, but it s not particularly likely that the direct beneficiaries of the operation of a gTLD stole an island chain and evicted the residents.
Are ccTLDs Ever Useful?
The answer to that question is an unqualified maybe .
I certainly don t think it s a good idea to register a domain under a ccTLD for vanity purposes: because it makes a word, is the same as a file extension you like, or because it looks cool.
Those ccTLDs that clearly represent and are associated with a particular country are more likely to be OK, because there is less impetus for the registry to try a naked cash grab.
Unfortunately, ccTLD registries have a disconcerting habit of changing their minds on whether they serve their geographic locality, such as when auDA decided to declare an open season in the .au namespace some years ago.
Essentially, while a ccTLD may have geographic connotations now, there s not a lot of guarantee that they won t fall victim to scope creep in the future.
Finally, it might be somewhat safer to register under a ccTLD if you live in the location involved.
At least then you might have a better idea of whether your domain is likely to get pulled out from underneath you.
Unfortunately, as the .eu example shows, living somewhere today is no guarantee you ll still be living there tomorrow, even if you don t move house.
In short, I d suggest sticking to gTLDs.
They re at least lower risk than ccTLDs.
+1, Helpful
If you ve found this post informative, why not buy me a refreshing beverage?
My typing fingers (both of them) thank you in advance for your generosity.
Footnotes
-
don t make the mistake of thinking that I approve of ICANN or how it operates; it s an omnishambles of poor governance and incomprehensible decision-making.
-
corresponding roughly, though not precisely (because everything has to be complicated, because humans are complicated), to the entries in the ISO standard for Codes for the representation of names of countries and their subdivisions , ISO 3166.
-
yes, the EU is not a country; it s part of the roughly, though not precisely caveat mentioned previously.
-
despite what domain registrars try very hard to imply, without falling foul of deceptive advertising regulations.
.sc domain names from US$25 to US$75. No reason, no warning, just pay up .
Who Is Even Getting That Money?
A closely related concern about ccTLDs is that some of the cool ones are assigned to countries that are not great.
The poster child for this is almost certainly Libya, which has the ccTLD ly .
While Libya was being run by a terrorist-supporting extremist, companies thought it was a great idea to have domain names that ended in .ly.
These domain registrations weren t (and aren t) cheap, and it s hard to imagine that at least some of that money wasn t going to benefit the Gaddafi regime.
Similarly, the British Indian Ocean Territory, which has the io ccTLD, was created in a colonialist piece of chicanery that expelled thousands of native Chagossians from Diego Garcia.
Money from the registration of .io domains doesn t go to the (former) residents of the Chagos islands, instead it gets paid to the UK government.
Again, I m not trying to suggest that all gTLD operators are wonderful people, but it s not particularly likely that the direct beneficiaries of the operation of a gTLD stole an island chain and evicted the residents.
Are ccTLDs Ever Useful?
The answer to that question is an unqualified maybe .
I certainly don t think it s a good idea to register a domain under a ccTLD for vanity purposes: because it makes a word, is the same as a file extension you like, or because it looks cool.
Those ccTLDs that clearly represent and are associated with a particular country are more likely to be OK, because there is less impetus for the registry to try a naked cash grab.
Unfortunately, ccTLD registries have a disconcerting habit of changing their minds on whether they serve their geographic locality, such as when auDA decided to declare an open season in the .au namespace some years ago.
Essentially, while a ccTLD may have geographic connotations now, there s not a lot of guarantee that they won t fall victim to scope creep in the future.
Finally, it might be somewhat safer to register under a ccTLD if you live in the location involved.
At least then you might have a better idea of whether your domain is likely to get pulled out from underneath you.
Unfortunately, as the .eu example shows, living somewhere today is no guarantee you ll still be living there tomorrow, even if you don t move house.
In short, I d suggest sticking to gTLDs.
They re at least lower risk than ccTLDs.
+1, Helpful
If you ve found this post informative, why not buy me a refreshing beverage?
My typing fingers (both of them) thank you in advance for your generosity.
Footnotes
-
don t make the mistake of thinking that I approve of ICANN or how it operates; it s an omnishambles of poor governance and incomprehensible decision-making.
-
corresponding roughly, though not precisely (because everything has to be complicated, because humans are complicated), to the entries in the ISO standard for Codes for the representation of names of countries and their subdivisions , ISO 3166.
-
yes, the EU is not a country; it s part of the roughly, though not precisely caveat mentioned previously.
-
despite what domain registrars try very hard to imply, without falling foul of deceptive advertising regulations.
.au namespace some years ago.
Essentially, while a ccTLD may have geographic connotations now, there s not a lot of guarantee that they won t fall victim to scope creep in the future.
Finally, it might be somewhat safer to register under a ccTLD if you live in the location involved.
At least then you might have a better idea of whether your domain is likely to get pulled out from underneath you.
Unfortunately, as the .eu example shows, living somewhere today is no guarantee you ll still be living there tomorrow, even if you don t move house.
In short, I d suggest sticking to gTLDs.
They re at least lower risk than ccTLDs.
+1, Helpful
If you ve found this post informative, why not buy me a refreshing beverage?
My typing fingers (both of them) thank you in advance for your generosity.
Footnotes
-
don t make the mistake of thinking that I approve of ICANN or how it operates; it s an omnishambles of poor governance and incomprehensible decision-making.
-
corresponding roughly, though not precisely (because everything has to be complicated, because humans are complicated), to the entries in the ISO standard for Codes for the representation of names of countries and their subdivisions , ISO 3166.
-
yes, the EU is not a country; it s part of the roughly, though not precisely caveat mentioned previously.
-
despite what domain registrars try very hard to imply, without falling foul of deceptive advertising regulations.
- don t make the mistake of thinking that I approve of ICANN or how it operates; it s an omnishambles of poor governance and incomprehensible decision-making.
- corresponding roughly, though not precisely (because everything has to be complicated, because humans are complicated), to the entries in the ISO standard for Codes for the representation of names of countries and their subdivisions , ISO 3166.
- yes, the EU is not a country; it s part of the roughly, though not precisely caveat mentioned previously.
- despite what domain registrars try very hard to imply, without falling foul of deceptive advertising regulations.
 I realize it s a bit late to start publicly organizing this, but better late
than never I m happy some Debian people I have directly contacted have
already expressed interest. So, lets make this public!
I realize it s a bit late to start publicly organizing this, but better late
than never I m happy some Debian people I have directly contacted have
already expressed interest. So, lets make this public!
 For all interested people who are reasonably close to central Argentina, or can
be persuaded to come here in a month s time You are all welcome!
It seems I managed to convince my good friend Mart n Bayo (some Debian people
will remember him, as he was present in DebConf19 in Curitiba, Brazil) to get
some facilities for us to have a nice Debian get-together in Central Argentina.
For all interested people who are reasonably close to central Argentina, or can
be persuaded to come here in a month s time You are all welcome!
It seems I managed to convince my good friend Mart n Bayo (some Debian people
will remember him, as he was present in DebConf19 in Curitiba, Brazil) to get
some facilities for us to have a nice Debian get-together in Central Argentina.

 The
The







 I got a new work laptop this year: A Thinkpad X1 Carbon (Gen 11). It wasn't the
one I wanted: I'd ordered an X1 Nano, which had a footprint very reminiscent to
me of my beloved
I got a new work laptop this year: A Thinkpad X1 Carbon (Gen 11). It wasn't the
one I wanted: I'd ordered an X1 Nano, which had a footprint very reminiscent to
me of my beloved  Insert obligatory "not THAT data" comment here
Insert obligatory "not THAT data" comment here
 If you don't know who Professor Julius Sumner Miller is, I highly recommend
If you don't know who Professor Julius Sumner Miller is, I highly recommend  No thanks, Bender, I'm busy tonight
No thanks, Bender, I'm busy tonight
 Inspired by a
Inspired by a 

 After seven years of service as member and secretary on the GHC Steering Committee, I have resigned from that role. So this is a good time to look back and retrace the formation of the GHC proposal process and committee.
In my memory, I helped define and shape the proposal process, optimizing it for effectiveness and throughput, but memory can be misleading, and judging from the paper trail in my email archives, this was indeed mostly Ben Gamari s and Richard Eisenberg s achievement: Already in Summer of 2016, Ben Gamari set up the
After seven years of service as member and secretary on the GHC Steering Committee, I have resigned from that role. So this is a good time to look back and retrace the formation of the GHC proposal process and committee.
In my memory, I helped define and shape the proposal process, optimizing it for effectiveness and throughput, but memory can be misleading, and judging from the paper trail in my email archives, this was indeed mostly Ben Gamari s and Richard Eisenberg s achievement: Already in Summer of 2016, Ben Gamari set up the 
 A very minor maintenance release, now at version 0.0.22, of
A very minor maintenance release, now at version 0.0.22, of 


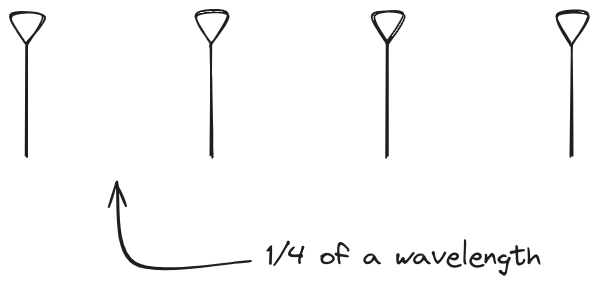 And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
And now let s take a look at the renders as we play with the configuration of
this array and make sure things look right. Our initial quarter-wavelength
spacing is very effective and has some outstanding performance characteristics.
Let s check to see that everything looks right as a first test.
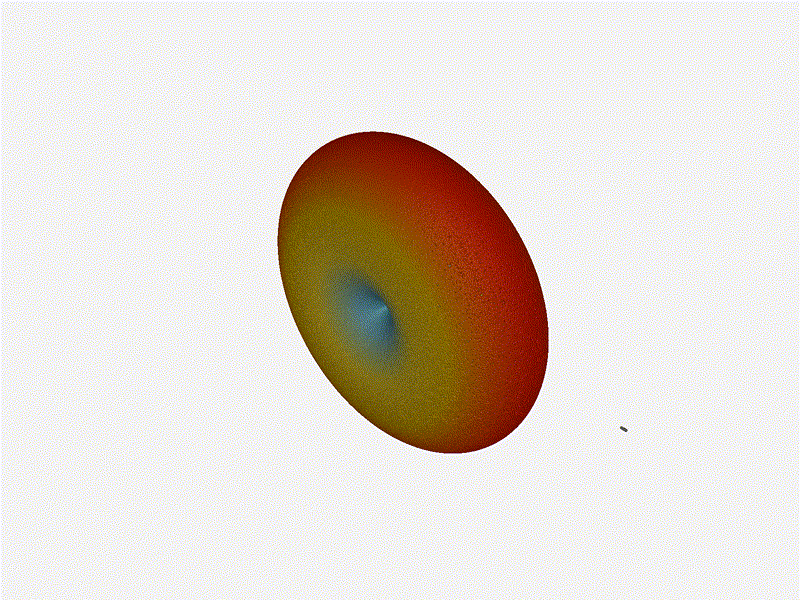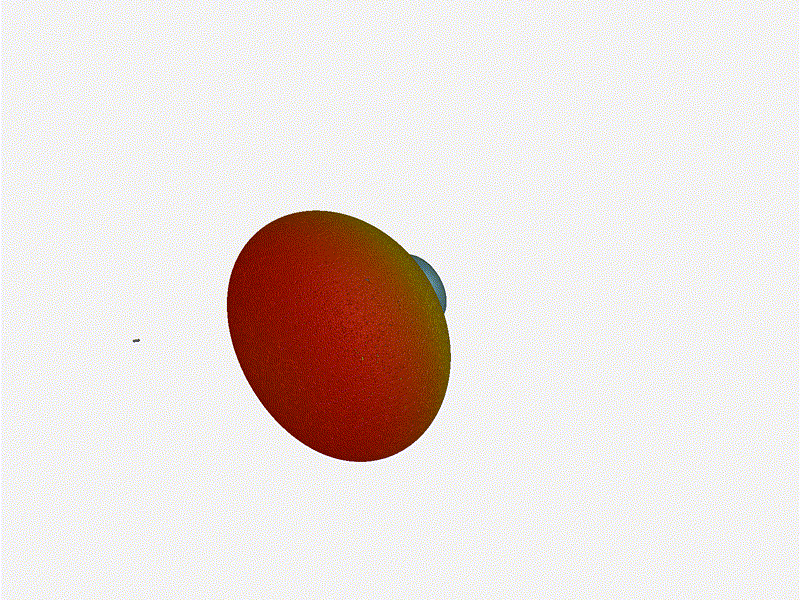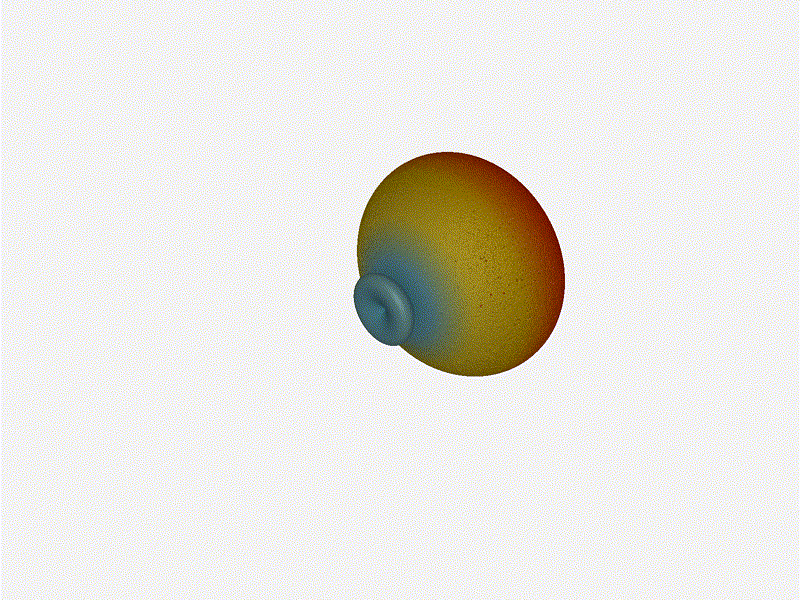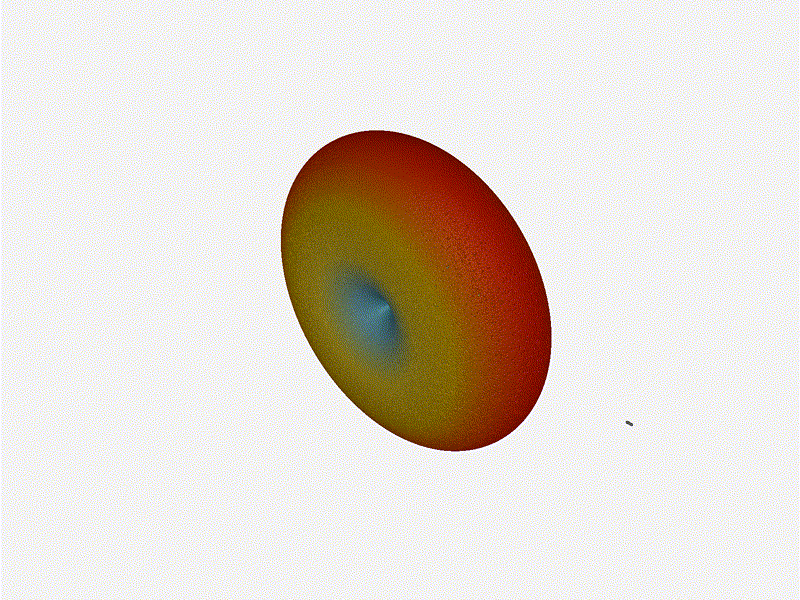
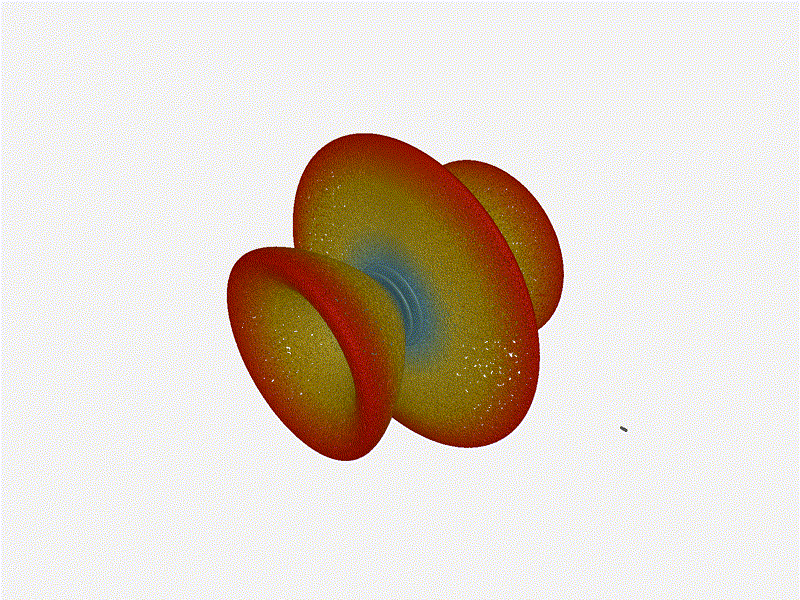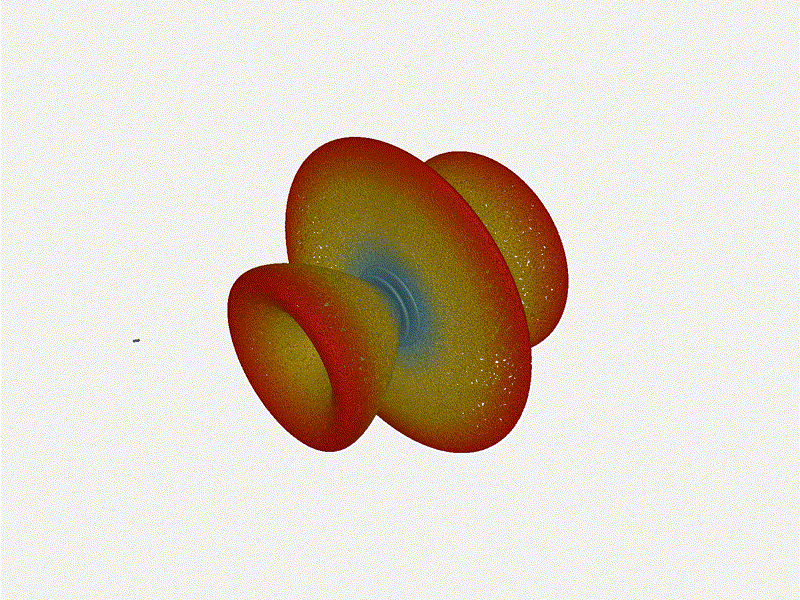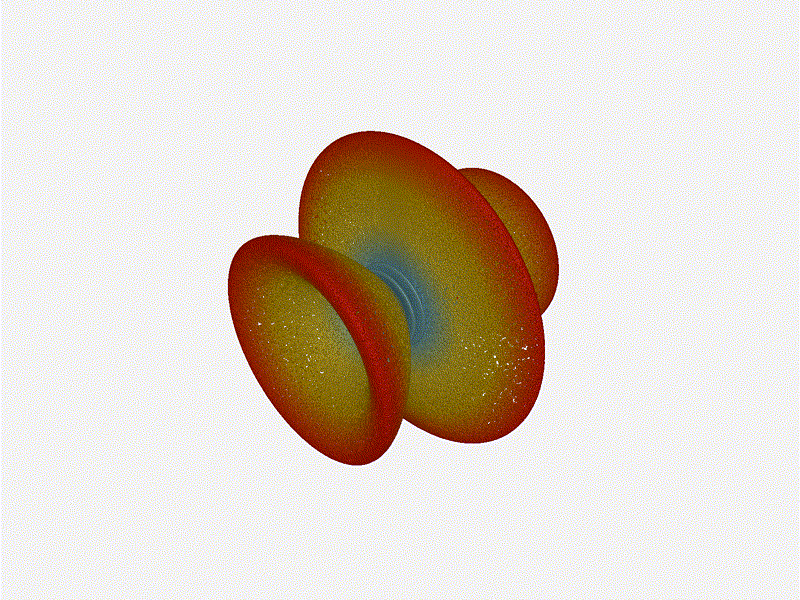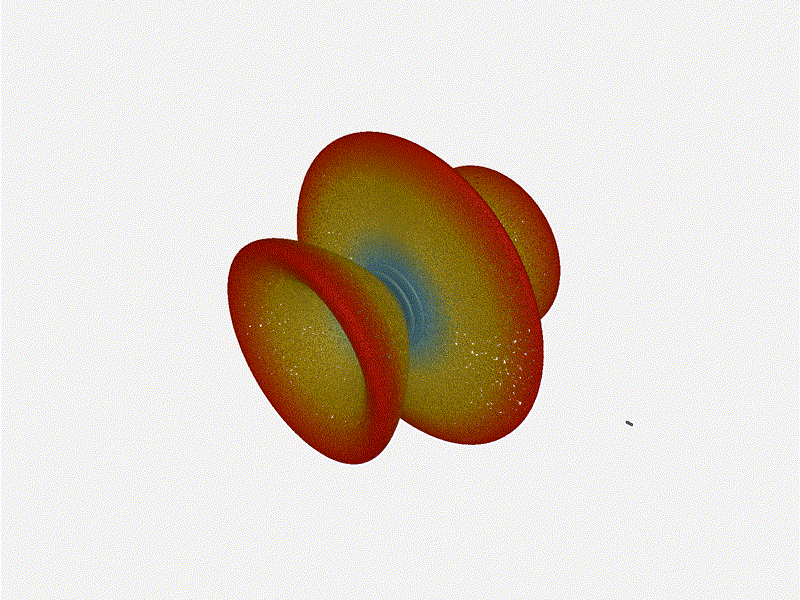

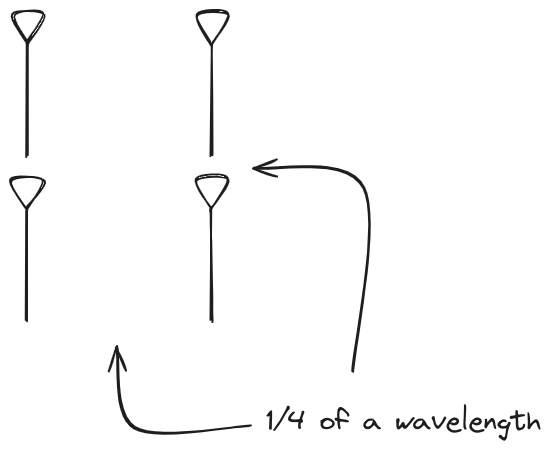 Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
Let s do the same as above and take a look at the renders as we play with the
configuration of this array and see what things look like. This configuration
should suppress the sidelobes and give us good performance, and even give us
some amount of control in elevation while we re at it.
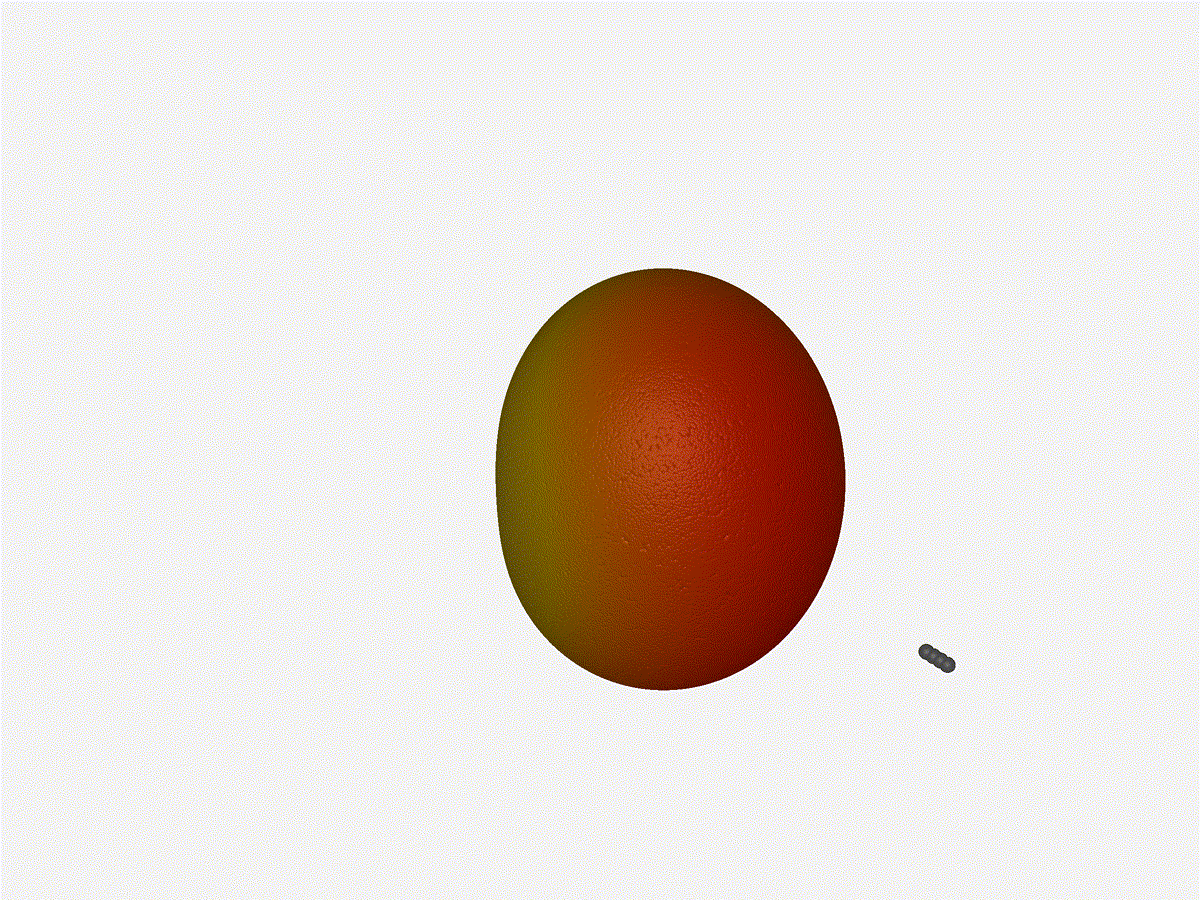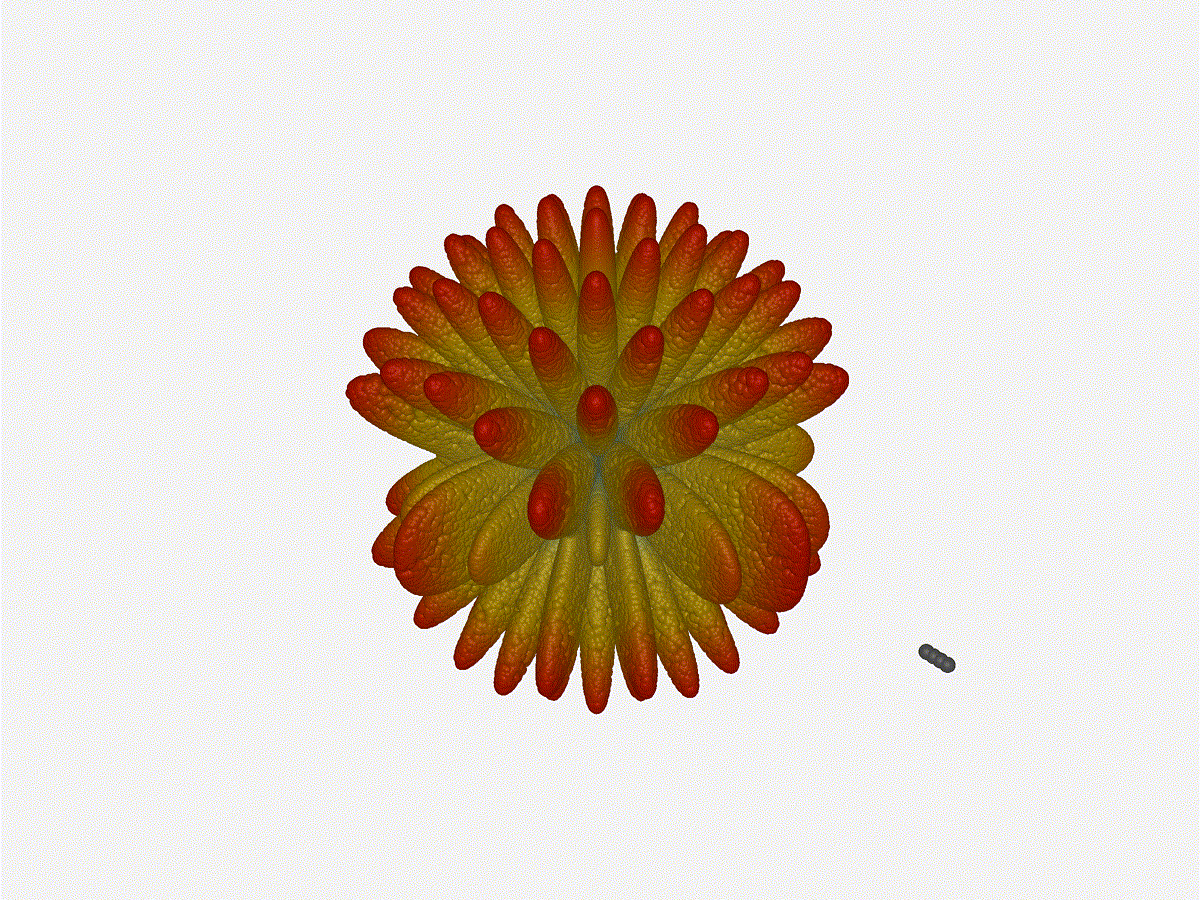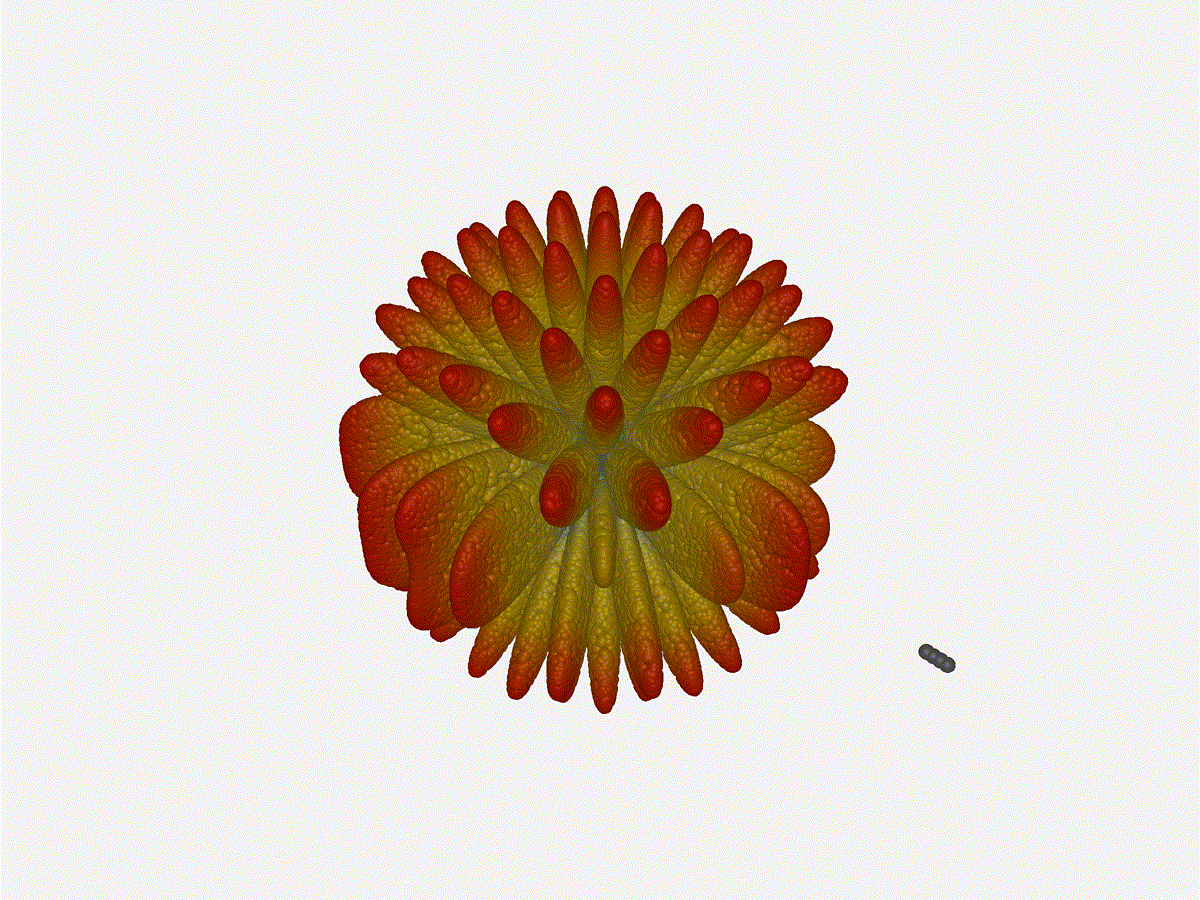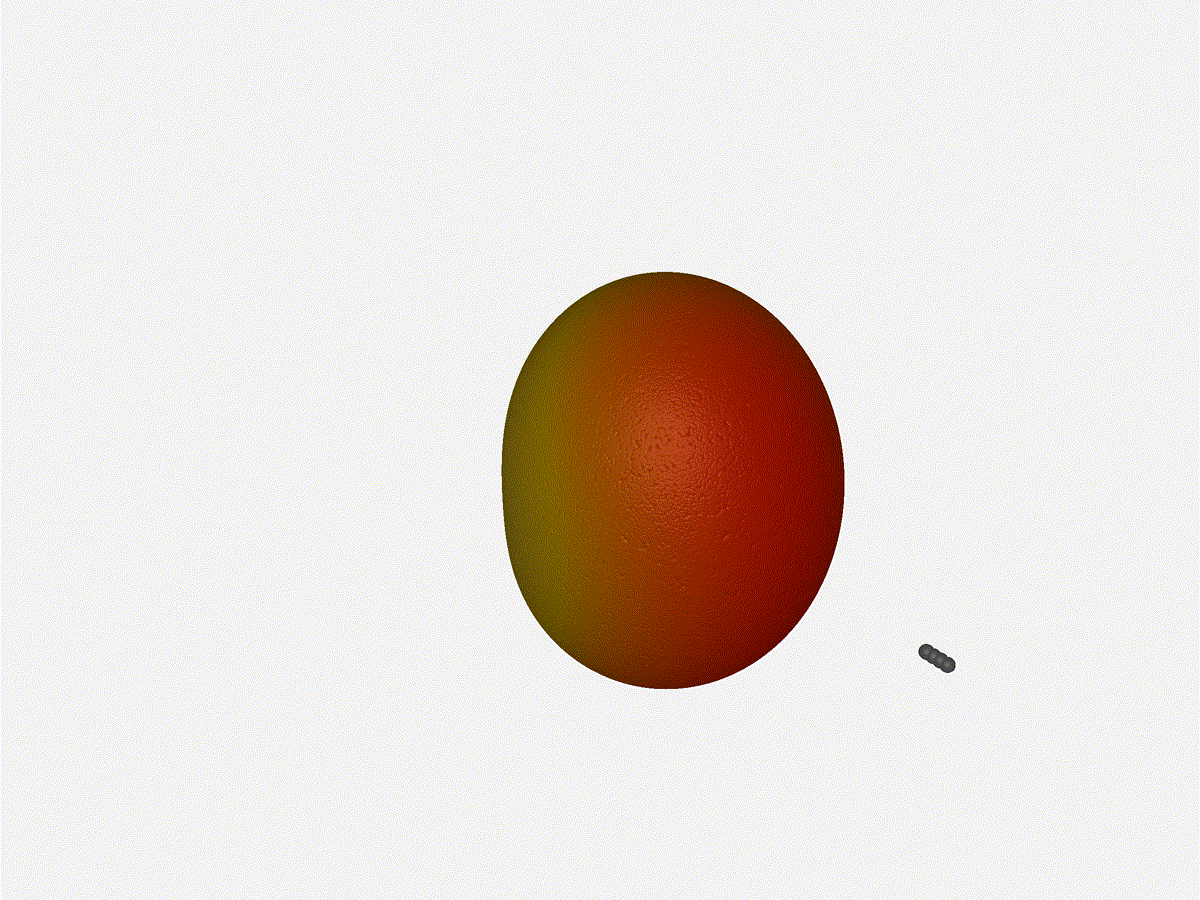
 Now that I m
Now that I m 










 I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.
I think while developing Wayland-as-an-ecosystem we are now entrenched into narrow concepts of how a desktop should work. While discussing Wayland protocol additions, a lot of concepts clash, people from different desktops with different design philosophies debate the merits of those over and over again never reaching any conclusion (just as you will never get an answer out of humans whether sushi or pizza is the clearly superior food, or whether CSD or SSD is better). Some people want to use Wayland as a vehicle to force applications to submit to their desktop s design philosophies, others prefer the smallest and leanest protocol possible, other developers want the most elegant behavior possible. To be clear, I think those are all very valid approaches.
But this also creates problems: By switching to Wayland compositors, we are already forcing a lot of porting work onto toolkit developers and application developers. This is annoying, but just work that has to be done. It becomes frustrating though if Wayland provides toolkits with absolutely no way to reach their goal in any reasonable way. For Nate s Photoshop analogy: Of course Linux does not break Photoshop, it is Adobe s responsibility to port it. But what if Linux was missing a crucial syscall that Photoshop needed for proper functionality and Adobe couldn t port it without that? In that case it becomes much less clear on who is to blame for Photoshop not being available.
A lot of Wayland protocol work is focused on the environment and design, while applications and work to port them often is considered less. I think this happens because the overlap between application developers and developers of the desktop environments is not necessarily large, and the overlap with people willing to engage with Wayland upstream is even smaller. The combination of Windows developers porting apps to Linux and having involvement with toolkits or Wayland is pretty much nonexistent. So they have less of a voice.

 I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.
I will also bring my two protocol MRs to their conclusion for sure, because as application developers we need clarity on what the platform (either all desktops or even just a few) supports and will or will not support in future. And the only way to get something good done is by contribution and friendly discussion.


 Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.
Figure 1: Content-Security-Policy browser communication
This is revolutionary, because it allows servers to receive feedback
in real time on errors that may be appearing in the browser s console.